OpenAI crawler útmutató – minden, amit tudnod kell az OpenAI webes feltérképezőiről
Szeretnéd tudni, hogyan működik az OpenAI crawler, mit gyűjt a weboldaladról, és hogyan szabályozhatod? Ebben a részletes útmutatóban bemutatom az OpenAI crawlereket, a robots.txt beállításokat, az AI keresők működését és a legjobb optimalizálási módszereket.
A mesterséges intelligencia már nem a jövő, hanem a jelen. Nap mint nap egyre többen kérdeznek a ChatGPT-től, az AI keresőktől és más intelligens rendszerektől, miközben ezek a szolgáltatások egyre gyakrabban hivatkoznak weboldalak tartalmaira. Emiatt ma már nem elég csak azt tudni, hogyan működik a Googlebot. Legalább ennyire fontos megérteni azt is, hogyan dolgoznak az OpenAI crawlerei, milyen adatokat gyűjtenek, és milyen szerepet játszanak az AI által adott válaszok mögött.
Sokan úgy gondolják, hogy a ChatGPT egyszerűen „elolvassa” az internetet, amikor kérdést teszel fel neki. A valóság ennél jóval összetettebb. Az OpenAI különböző webes robotokat használ eltérő feladatokra: egyesek nyilvános weboldalakat térképeznek fel, mások a keresési funkciókat támogatják, míg bizonyos robotok kizárólag akkor látogatnak meg egy oldalt, amikor egy felhasználó erre kifejezetten kéri az AI-t. Ha ismered ezek működését, sokkal tudatosabban alakíthatod a weboldalad AI-láthatóságát.
Ez különösen fontos, ha vállalkozásod van, SEO-val foglalkozol, vagy azt szeretnéd, hogy a weboldalad a jövő AI-alapú kereséseiben is hiteles forrásként jelenjen meg. Legyen szó egy SEO ügynökségről, egy menyasszonyi ruhaszalonról, egy kertészeti weboldalról, egy villanyszerelő vállalkozásról vagy egy klímatelepítő cégről, az AI rendszerek egyre inkább a jól strukturált, megbízható és szakmailag hiteles tartalmakat részesítik előnyben.
Az OpenAI crawlerek működésének megértése nem csupán technikai érdekesség. Segít eldönteni, hogy mely robotokat szeretnéd engedélyezni vagy tiltani, hogyan állítsd be megfelelően a robots.txt fájlt, miként építs AI-barát tartalomstruktúrát, és hogyan növeld annak az esélyét, hogy a weboldalad a jövő intelligens keresőiben is megjelenjen.
Ebben a részletes útmutatóban végigvezetlek az OpenAI crawlerek világán. Megmutatom, milyen robotokat használ az OpenAI, miben különböznek egymástól, hogyan működnek, milyen adatokat gyűjtenek, hogyan szabályozhatod a hozzáférésüket, és ami talán a legfontosabb: hogyan készítheted fel a weboldaladat arra, hogy az AI rendszerek könnyebben megértsék, hitelesnek tekintsék és gyakrabban használják fel a tartalmadat.
Tartalomjegyzék
- Mi az az OpenAI crawler?
- Miért használ crawlereket az OpenAI?
- Milyen OpenAI crawlerek léteznek?
- Hogyan működik egy OpenAI crawler?
- Mit gyűjt egy OpenAI crawler egy weboldalról?
- OpenAI crawler és Googlebot – mi a különbség?
- Hogyan ellenőrizheted, hogy járt-e nálad az OpenAI crawler?
- Hogyan szabályozhatod az OpenAI crawler működését?
- Robots.txt beállítások OpenAI crawlerekhez
- Mit jelent mindez SEO és AI keresőoptimalizálás szempontjából?
- Hogyan optimalizáld a weboldalad az OpenAI számára?
- Gyakori hibák OpenAI crawler optimalizálás során
- OpenAI crawler ellenőrző lista
- Összegzés
- GYIK ❓
Mi az az OpenAI crawler?
Bevezetőként érdemes tisztázni, hogy amikor az emberek az „OpenAI crawler” kifejezést használják, valójában nem egyetlen robotra gondolnak. Az OpenAI több különböző webes crawlert is üzemeltet, amelyek eltérő feladatokat látnak el. Van, amelyik a keresési funkciókat támogatja, van, amelyik a felhasználók kérésére látogat meg egy weboldalt, és olyan is létezik, amelyet az AI modellek fejlesztésével kapcsolatban használnak. Éppen ezért fontos megérteni, hogy az OpenAI crawler valójában egy gyűjtőfogalom.
Mi az az OpenAI crawler?
Az OpenAI crawler olyan automatikus webes robot (crawler vagy web crawler), amely nyilvánosan elérhető weboldalakat látogat meg, azok tartalmát elemzi, és meghatározott célokra dolgozza fel. A működése sok tekintetben hasonlít a hagyományos keresőmotorok robotjaihoz, ugyanakkor nem ugyanazt a feladatot végzi, mint például a Googlebot.
Míg a Google elsődleges célja a weboldalak indexelése és rangsorolása a Google keresőjében, addig az OpenAI különböző robotjai más-más feladatokat látnak el. Egyes crawlerek a ChatGPT keresési funkcióját támogatják, mások egy felhasználó kérésére töltik le egy adott oldal tartalmát, míg bizonyos robotok az OpenAI rendszereinek fejlesztéséhez kapcsolódó folyamatokban vesznek részt.
Az OpenAI crawlerei a weboldalak feltérképezése során elsősorban olyan információkat vizsgálnak, mint:
- az oldal szöveges tartalma
- a címsorok (H1–H6)
- a belső és külső linkek
- a strukturált adatok (Schema.org)
- a metaadatok
- a weboldal felépítése
- az egyes témák és entitások közötti kapcsolatok
A crawlerek működését a weboldal tulajdonosa robots.txt szabályokkal részben szabályozhatja. Ennek segítségével eldöntheted, hogy mely OpenAI robotok férhetnek hozzá az oldaladhoz, és melyek nem.
OpenAI crawler és ChatGPT – nem ugyanaz
Az egyik leggyakoribb félreértés, hogy sokan magát a ChatGPT-t tekintik crawlernek. Ez azonban nem helyes.
A ChatGPT egy mesterséges intelligencia modell, amely kérdésekre válaszol és szöveget generál. Az OpenAI crawlerei ezzel szemben olyan háttérben működő robotok, amelyek weboldalakat keresnek fel és dolgoznak fel meghatározott célok érdekében.
Egyszerűen fogalmazva:
- A crawler begyűjti vagy eléri az információt.
- A ChatGPT ezt az információt felhasználva segít válaszokat adni.
Ez a két szerepkör teljesen eltér egymástól, még akkor is, ha ugyanahhoz az ökoszisztémához tartoznak.
Miért fontos ismerni az OpenAI crawlereket?
Az AI-alapú keresések és válaszmotorok rohamos terjedésével egyre fontosabbá válik, hogy ne csak a hagyományos keresőoptimalizálásra figyelj. Ha szeretnéd, hogy weboldalad a jövőben is könnyen értelmezhető legyen a mesterséges intelligencia számára, érdemes megértened, hogyan működnek az OpenAI crawlerei, milyen tartalmakat részesítenek előnyben, és hogyan szabályozhatod a hozzáférésüket.
Akár egy SEO szakértő weboldalát, egy kertészeti blogot, egy villanyszerelő vállalkozás honlapját, egy klímás szolgáltató oldalát vagy egy menyasszonyi ruhaszalont üzemeltetsz, az AI rendszerek számára jól strukturált, hiteles és naprakész tartalom egyre nagyobb versenyelőnyt jelenthet. Az OpenAI crawlerek működésének megismerése ezért már nem csupán technikai érdekesség, hanem az AI keresőoptimalizálás egyik alapvető eleme.
Miért használ crawlereket az OpenAI?
Milyen OpenAI crawlerek léteznek?
Sokan úgy gondolják, hogy az OpenAI egyetlen webes robotot használ, pedig ez ma már nem igaz. Az OpenAI több különböző crawlert (user agentet) működtet, amelyek eltérő feladatokat látnak el. Van, amelyik a ChatGPT keresési funkcióját támogatja, van, amelyik a felhasználók kérésére látogat meg egy weboldalt, és olyan is, amelyet az AI modellek fejlesztéséhez használnak. Ezeket külön-külön is szabályozhatod a robots.txt fájl segítségével.
Az OpenAI crawlereinek áttekintése
| OpenAI crawler | Fő feladata | Szabályozható robots.txt-ben | Mire használják? |
|---|---|---|---|
| GPTBot | Nyilvános weboldalak feltérképezése AI modellek fejlesztéséhez | ✅ Igen | Nyilvánosan elérhető tartalmak gyűjtése a jövőbeli modellek fejlesztéséhez |
| OAI-SearchBot | ChatGPT Search támogatása | ✅ Igen | Weboldalak feltérképezése és megjelenítése a ChatGPT keresési találatai között |
| ChatGPT-User | Felhasználó által kezdeményezett oldalbetöltések | ✅ Igen | Egy adott weboldal lekérése, amikor egy felhasználó ezt kéri a ChatGPT-től |
| OAI-AdsBot | ChatGPT hirdetések ellenőrzése | ✅ Igen | A ChatGPT-ben megjelenő hirdetések céloldalainak ellenőrzése és értékelése. |
GPTBot – az AI modellek fejlesztését támogató crawler
A GPTBot volt az OpenAI első hivatalosan dokumentált webes robotja. Feladata, hogy nyilvánosan hozzáférhető weboldalakat térképezzen fel, amelyek – az OpenAI irányelveinek megfelelően – felhasználhatók a jövőbeli generatív AI modellek fejlesztéséhez. A weboldal tulajdonosa dönthet úgy, hogy ezt engedélyezi vagy letiltja a robots.txt fájlban.
Ha például egy SEO blogot, kertészeti portált vagy villanyszerelő vállalkozás weboldalát üzemelteted, eldöntheted, hogy szeretnéd-e, hogy a nyilvános tartalmaid bekerüljenek ebbe a folyamatba.
OAI-SearchBot – a ChatGPT keresőrobotja
Az OAI-SearchBot teljesen más célt szolgál. Ez a crawler a ChatGPT Search működését támogatja, vagyis azt segíti elő, hogy egy weboldal megjelenhessen a ChatGPT keresési találatai és hivatkozásai között.
Ha ezt a robotot letiltod, akkor a weboldalad nem lesz jogosult megjelenni a ChatGPT Search válaszaiban, miközben ez nem befolyásolja a Google helyezéseidet. Éppen ezért sok weboldal tulajdonosa engedélyezi az OAI-SearchBotot, még akkor is, ha a GPTBotot letiltja.
ChatGPT-User – amikor a felhasználó kéri az oldal betöltését
A ChatGPT-User nem végez folyamatos webes feltérképezést. Ez a user agent akkor jelenik meg, amikor egy felhasználó arra kéri a ChatGPT-t, hogy látogasson meg vagy elemezzen egy konkrét weboldalt.
Például:
- „Elemezd ezt a weboldalt!”
- „Foglald össze ezt a cikket!”
- „Mit ír ez az oldal a hőszivattyúkról?”
Ilyenkor a ChatGPT-User töltheti le az adott oldal tartalmát, hogy azt a mesterséges intelligencia feldolgozhassa. Ez nem automatikus indexelés, hanem egy konkrét felhasználói kéréshez kapcsolódó művelet.
OAI-AdsBot – a ChatGPT hirdetéseinek ellenőrző robotja
Az OpenAI dokumentációjában újabb user agentként jelent meg az OAI-AdsBot, amely kizárólag a ChatGPT-ben futó hirdetésekhez kapcsolódik.
Feladata többek között:
- a hirdetések céloldalának ellenőrzése;
- az OpenAI hirdetési szabályainak vizsgálata;
- a céloldal tartalmának elemzése a hirdetések megfelelő megjelenítése érdekében.
Ez a crawler nem AI modelltanításra szolgál, hanem kizárólag a hirdetési rendszer működését támogatja. Ha nem futtatsz ChatGPT-hirdetéseket, nagy valószínűséggel nem fog találkozni a weboldaladdal.
Miért fontos ismerni a különbségeket?
A legnagyobb hiba, amit sok weboldal-tulajdonos elkövet, hogy minden OpenAI robotot ugyanolyannak tekint. Pedig mindegyik más feladatot lát el, és külön-külön szabályozható.
Ha például azt szeretnéd, hogy a weboldalad megjelenhessen a ChatGPT keresési találatai között, de nem szeretnéd, hogy a nyilvános tartalmad AI modellek fejlesztéséhez legyen felhasználható, akkor engedélyezheted az OAI-SearchBotot, miközben letiltod a GPTBotot. Ez a rugalmasság lehetővé teszi, hogy saját céljaidnak megfelelően kezeld az OpenAI crawlereinek hozzáférését, és tudatos AI keresőoptimalizálási stratégiát alakíts ki.
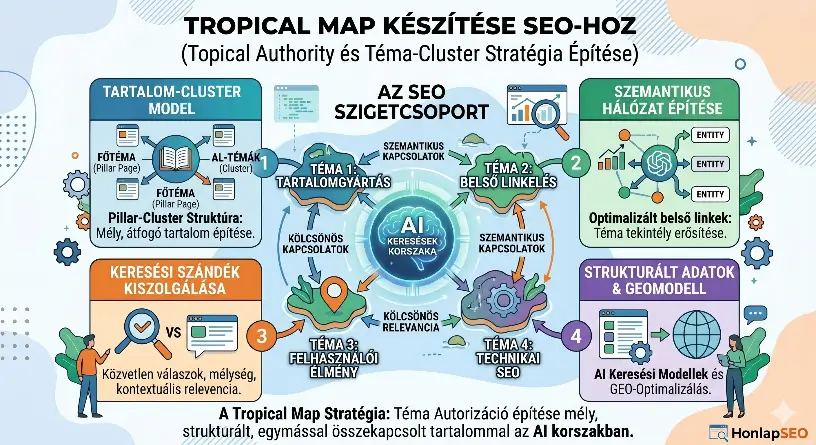
Hogyan működik egy OpenAI crawler?
Első ránézésre úgy tűnhet, hogy egy crawler egyszerűen letölti egy weboldal tartalmát, valójában azonban ennél jóval összetettebb folyamatról van szó. Egy modern OpenAI crawler nemcsak elolvassa az oldal szövegét, hanem megvizsgálja annak felépítését, értelmezi a tartalom szerkezetét, felismeri az entitásokat és elemzi a különböző információk közötti kapcsolatokat. Ennek köszönhetően az AI rendszerek nem pusztán kulcsszavakat látnak, hanem megpróbálják megérteni a weboldal jelentését és témáját.
Bár az OpenAI nem teszi közzé crawlereinek teljes működési folyamatát, a nyilvánosan ismert dokumentációk és az általános webes crawler-technológiák alapján jól bemutatható, hogyan zajlik egy tipikus feltérképezés.
1. URL-ek felfedezése
A folyamat mindig egy URL megtalálásával kezdődik. Egy crawler többféleképpen is rábukkanhat egy weboldalra:
- más weboldalakról érkező linkeken keresztül;
- XML sitemap segítségével;
- nyilvánosan elérhető hivatkozások alapján;
- amikor egy felhasználó a ChatGPT-ben egy konkrét weboldal elemzését kéri.
Minél több minőségi hivatkozás mutat egy oldalra, annál könnyebben találhat rá egy crawler.
2. A robots.txt fájl ellenőrzése
Mielőtt letöltené az oldal tartalmát, a crawler megnézi a weboldal robots.txt fájlját.
Ebben a fájlban határozhatod meg, hogy mely robotok férhetnek hozzá bizonyos oldalakhoz vagy könyvtárakhoz.
Például:
- engedélyezheted az OAI-SearchBot működését;
- letilthatod a GPTBotot;
- korlátozhatod bizonyos mappák feltérképezését.
Ha a robots.txt tiltja az adott crawler számára az oldal elérését, akkor a robot tiszteletben tartja ezt a szabályt, és nem tölti le a tiltott tartalmat.
3. Az oldal letöltése
Ha nincs tiltás, a crawler HTTP-kérést küld a szervernek, majd letölti az oldal HTML-kódját.
Ezután megvizsgálja többek között:
- a teljes szöveget;
- a HTML szerkezetet;
- a címsorokat;
- a metaadatokat;
- a képeket;
- a linkeket;
- a strukturált adatokat.
Ezek együttesen segítenek megérteni, hogy miről szól az oldal.
4. A tartalom elemzése
A letöltött oldal feldolgozása után kezdődik a valódi elemzés.
A crawler nem csupán megszámolja a kulcsszavakat, hanem vizsgálja például:
- mi a fő téma;
- milyen altémák szerepelnek;
- logikusan épülnek-e fel a címsorok;
- milyen kérdésekre ad választ a cikk;
- mennyire részletes az információ.
Egy jól felépített SEO útmutató például sokkal könnyebben értelmezhető, mint egy rövid, rendezetlen szöveg.
5. Entitások felismerése
A modern AI rendszerek számára az egyik legfontosabb feladat az entitások felismerése.
Egy crawler képes azonosítani például:
- személyeket;
- vállalkozásokat;
- márkákat;
- helyszíneket;
- termékeket;
- szolgáltatásokat.
Ha például egy cikkben többször szerepel egy ismert villanyszerelő cég neve, egy klímatelepítő vállalkozás vagy egy menyasszonyi ruhaszalon, akkor a rendszer felismeri, hogy ezek önálló entitások, és kapcsolatba hozza őket a cikk témájával.
6. Kapcsolatok és témák feltérképezése
Az OpenAI crawlerei nemcsak egyetlen oldalt vizsgálnak, hanem azt is elemzik, hogyan kapcsolódnak egymáshoz a különböző tartalmak.
Figyelhetik például:
- a belső linkeket;
- a témaklasztereket;
- a kapcsolódó cikkeket;
- a kategóriák felépítését;
- az oldal teljes tudásbázisát.
Ha például egy SEO weboldalon külön cikkek készülnek a technikai SEO-ról, a linképítésről, a strukturált adatokról, az AI keresőoptimalizálásról és a topical authorityről, akkor a crawler könnyebben felismeri, hogy az oldal mély szakértelemmel foglalkozik a keresőoptimalizálás témájával.
7. Strukturált adatok feldolgozása
A crawlerek kiemelt figyelmet fordíthatnak a Schema.org strukturált adatokra, mert ezek egyértelmű információkat adnak a weboldal tartalmáról.
Különösen hasznosak lehetnek:
ArticleFAQPageOrganizationLocalBusinessPersonProductServiceBreadcrumbList
A strukturált adatok segítenek abban, hogy az AI gyorsabban és pontosabban értelmezze a tartalom jelentését.
8. A weboldal folyamatos újralátogatása
A feltérképezés nem egyszeri folyamat. Az OpenAI egyes crawlerei időről időre újra felkereshetik a weboldalakat, különösen akkor, ha azok rendszeresen frissülnek vagy új tartalmak jelennek meg rajtuk.
Ezért érdemes folyamatosan:
- frissíteni a régi cikkeket;
- új témákat feldolgozni;
- javítani a belső linkelést;
- naprakészen tartani a strukturált adatokat.
A rendszeres frissítések azt jelzik, hogy a weboldal aktív, és értékes információkat kínál.
Az OpenAI crawler működésének folyamata
| Lépés | Mi történik? | Miért fontos? |
|---|---|---|
| 1. URL felfedezése | A crawler megtalálja a weboldalt linkek, sitemap vagy felhasználói kérés alapján. | Ez indítja el a feltérképezési folyamatot. |
| 2. Robots.txt ellenőrzése | Megvizsgálja, hogy engedélyezett-e az oldal feltérképezése. | A weboldal tulajdonosa szabályozhatja a hozzáférést. |
| 3. HTML letöltése | Letölti az oldal forráskódját és tartalmát. | Ez biztosítja az elemzéshez szükséges adatokat. |
| 4. Tartalom elemzése | Feldolgozza a szöveget, címsorokat, metaadatokat és linkeket. | Segít megérteni az oldal témáját és szerkezetét. |
| 5. Entitások felismerése | Azonosítja a személyeket, cégeket, márkákat, helyeket és szolgáltatásokat. | Pontosabb szemantikus értelmezést tesz lehetővé. |
| 6. Kapcsolatok feltérképezése | Elemzi a belső linkeket és a témák közötti összefüggéseket. | Felméri a weboldal szakmai mélységét és topical authority-jét. |
| 7. Strukturált adatok értelmezése | Feldolgozza a Schema.org jelöléseket. | Gyorsabb és egyértelműbb tartalomértelmezést biztosít. |
| 8. Újralátogatás | Időnként ismét felkeresi a weboldalt a változások ellenőrzésére. | A friss és naprakész tartalmak nagyobb eséllyel maradnak relevánsak. |
Mit jelent ez a gyakorlatban?
Egy OpenAI crawler tehát jóval többet tesz annál, mint hogy egyszerűen letölt egy weboldalt. Megpróbálja megérteni annak teljes jelentését, szerkezetét és szakmai hitelességét. Ezért egy AI-barát weboldal nemcsak kulcsszavakból áll, hanem logikusan felépített tartalomból, jól szervezett témaklaszterekből, megfelelő belső linkelésből, strukturált adatokból és valódi szakértelmet tükröző információkból. Minél könnyebben értelmezhető egy oldal az AI számára, annál nagyobb az esélye annak, hogy a jövő AI-alapú kereséseiben és válaszaiban is értékes forrásként jelenjen meg.
Mit gyűjt egy OpenAI crawler egy weboldalról?
Amikor egy OpenAI crawler felkeres egy weboldalt, nem egyszerűen „elolvassa” annak tartalmát. A célja, hogy minél pontosabban megértse, miről szól az oldal, milyen információkat tartalmaz, és hogyan kapcsolódik más témákhoz. Ehhez a robot a HTML-kódban található számos elemet elemez, majd ezekből egy összetett képet alakít ki a weboldalról.
Fontos azonban kiemelni, hogy az OpenAI nem teszi közzé részletesen, milyen adatokat dolgoz fel minden egyes crawler, ezért az alábbi lista a nyilvános dokumentációkra és az általánosan ismert webes crawler-technológiák működésére épül. A felsorolt elemek azok, amelyeket a legtöbb modern crawler – így az OpenAI robotjai is – képesek értelmezni.
A weboldal szöveges tartalma
A legfontosabb információ természetesen maga a szöveg. A crawler elemzi:
- a teljes cikk tartalmát;
- a bekezdéseket;
- a felsorolásokat;
- a kiemelt részeket;
- a kérdés-válasz blokkokat.
Nem pusztán azt figyeli, hogy hányszor szerepel egy kulcsszó, hanem azt is, hogy mennyire átfogó, logikus és hasznos a tartalom.
Egy részletes útmutató például a hőszivattyúk működéséről vagy egy teljes SEO kézikönyv sokkal több kontextust ad, mint egy néhány száz szavas rövid ismertető.
A címsorok és a tartalom szerkezete
A H1, H2, H3 és további címsorok segítenek a crawlernek megérteni, hogyan épül fel az oldal.
Egy jól strukturált cikkből gyorsan kiderül például:
- mi a fő téma;
- milyen altémák szerepelnek;
- milyen sorrendben követik egymást az információk.
Ez jelentősen megkönnyíti az AI számára a tartalom értelmezését.
A belső és külső linkek
A crawlerek a linkeket is elemzik.
Vizsgálhatják például:
- milyen kapcsolódó cikkekre mutatsz;
- milyen témák között építettél kapcsolatot;
- milyen külső, hiteles forrásokat használsz.
Ha például egy AI SEO cikkből hivatkozol a strukturált adatokról, a topical authority-ről és az AI Visibility-ről szóló útmutatókra, az segíthet megmutatni, hogy a weboldalad mélyen feldolgozza a témát.
A strukturált adatok (Schema.org)
A strukturált adatok az egyik legértékesebb információforrást jelenthetik egy crawler számára.
Ezekből pontosan megállapítható például:
- ki a szerző;
- mikor készült a cikk;
- milyen vállalkozásról szól az oldal;
- milyen szolgáltatásokat kínálsz;
- milyen kérdések és válaszok találhatók a tartalomban.
A strukturált adatok olyanok, mintha egy külön „magyarázó réteget” adnál a weboldaladhoz, amelyet az AI könnyebben tud értelmezni.
Az entitások felismerése
A modern mesterséges intelligencia már nem csak kulcsszavakban gondolkodik.
A crawler felismerheti például:
- személyeket;
- vállalkozásokat;
- márkákat;
- városokat;
- termékeket;
- szolgáltatásokat.
Ha például egy cikkben többször szerepel egy ismert SEO szakértő neve vagy egy adott vállalkozás, akkor az AI képes ezeket önálló entitásként kezelni, és kapcsolatba hozni a témával.
A képek és azok leírásai
Bár a szöveg továbbra is elsődleges, a crawlerek a képekhez kapcsolódó információkat is vizsgálhatják.
Ilyenek például:
- alt szövegek;
- fájlnevek;
- képaláírások;
- környező szöveg.
Egy „hoszivattyu-levego-viz-rendszer.jpg” fájlnév vagy egy jól megírt alt szöveg sokkal több információt hordoz, mint egy „IMG_4582.jpg” elnevezés.
A metaadatok
A crawler figyelmet fordíthat az oldal metaadataira is.
Ide tartozhatnak:
- a title tag;
- a meta description;
- a canonical URL;
- a nyelvi beállítások;
- az Open Graph adatok.
Ezek segítenek meghatározni, hogy mi az oldal elsődleges témája, és hogyan jelenjen meg különböző rendszerekben.
A weboldal technikai felépítése
Az OpenAI crawlerei valószínűleg a technikai jeleket sem hagyják figyelmen kívül.
Vizsgálhatják például:
- HTTPS használatát;
- mobilbarát kialakítást;
- oldalbetöltési sebességet;
- hibás linkeket;
- átirányításokat;
- HTML minőségét.
Ezek nemcsak a felhasználói élményt javítják, hanem megkönnyítik a crawler számára az oldal feldolgozását is.
Milyen elemeket elemezhet egy OpenAI crawler?
| Elem | Miért fontos? | AI számára jelentősége |
|---|---|---|
| Szöveges tartalom | Meghatározza a weboldal fő témáját és szakmai mélységét. | Az AI ebből érti meg, miről szól az oldal. |
| H1–H6 címsorok | Logikus szerkezetet biztosítanak. | Segítik a témák és altémák felismerését. |
| Belső linkek | Összekapcsolják a kapcsolódó tartalmakat. | Feltárják a témaklasztereket és a topical authority-t. |
| Külső hivatkozások | Hiteles forrásokra mutathatnak. | Növelhetik a tartalom megbízhatóságát. |
| Schema.org strukturált adatok | Egyértelmű információkat adnak a tartalomról. | Gyorsabb és pontosabb értelmezést tesznek lehetővé. |
| Metaadatok | Leírják az oldal fő tartalmát. | Segítik a tartalom azonosítását. |
| Képek és alt szövegek | Kiegészítő információkat hordoznak. | Javítják a vizuális tartalom értelmezését. |
| Entitások | Azonosítják a személyeket, cégeket, márkákat és helyeket. | Segítik a szemantikus kapcsolatok kialakítását. |
| Technikai elemek | Biztosítják a könnyű feltérképezhetőséget. | Hatékonyabb feldolgozást tesznek lehetővé. |
Nem csak adatokat gyűjt, hanem összefüggéseket is keres
A legfontosabb különbség a régebbi crawlerekhez képest, hogy az OpenAI robotjai nem pusztán adatokat gyűjtenek, hanem azok közötti kapcsolatokat is igyekeznek felismerni. Nemcsak azt látják, hogy egy oldalon szerepel a „SEO” vagy a „hőszivattyú” szó, hanem azt is, hogyan kapcsolódnak ezek más fogalmakhoz, mennyire részletes a tartalom, milyen szakmai mélységet képvisel, és mennyire hiteles az információ.
Éppen ezért egy AI számára jól optimalizált weboldal nem a kulcsszavak ismételgetésére épül, hanem átgondolt tartalomstruktúrára, világos címsorokra, összefüggő témaklaszterekre, strukturált adatokra és valódi szakmai értéket nyújtó tartalomra. Ez az, ami hosszú távon növelheti annak esélyét, hogy az oldalad az AI-alapú keresések és válaszok megbízható forrásává váljon.
OpenAI crawler és Googlebot – mi a különbség?
Első pillantásra könnyű azt gondolni, hogy az OpenAI crawlerei és a Googlebot ugyanazt a feladatot végzik. Mindkettő weboldalakat látogat meg, HTML-kódot tölt le, elemzi a tartalmat és követi a hivatkozásokat. A legfontosabb különbség azonban a céljukban rejlik.
A Googlebot elsődleges feladata, hogy feltérképezze a webet, indexelje az oldalakat, majd ezek alapján rangsorolja őket a Google kereső találatai között. Az OpenAI crawlerei ezzel szemben nem hagyományos keresőindexet építenek, hanem különböző AI-szolgáltatásokat támogatnak, például a ChatGPT Search működését, a felhasználók által kért weboldalak feldolgozását vagy – a GPTBot esetében – a jövőbeli AI modellek fejlesztését.
Ez azt jelenti, hogy ugyanaz a weboldal két teljesen eltérő célból is meglátogatható: egyszer azért, hogy megjelenjen a Google keresési találatai között, máskor pedig azért, hogy egy AI rendszer könnyebben értelmezhesse vagy felhasználhassa a tartalmát.
OpenAI crawler és Googlebot összehasonlítása
| Tulajdonság | Googlebot | OpenAI crawlerek |
|---|---|---|
| Elsődleges cél | Weboldalak indexelése és rangsorolása a Google Keresőben | AI-szolgáltatások támogatása (pl. ChatGPT Search, felhasználói lekérések, modellfejlesztés) |
| Keresőindex építése | ✅ Igen | ❌ Nem hagyományos keresőindexet épít |
| AI válaszok támogatása | Közvetetten (AI Overviews stb.) | ✅ Igen, közvetlenül AI-rendszereket támogat |
| Robots.txt tiszteletben tartása | ✅ Igen | ✅ Igen |
| Strukturált adatok feldolgozása | ✅ Igen | ✅ Igen |
| Belső linkek elemzése | ✅ Igen | ✅ Igen |
| Entitások felismerése | ✅ Igen | ✅ Igen |
| Topical authority értelmezése | Valószínűleg igen | Valószínűleg igen, különösen szemantikai összefüggések alapján |
| Felhasználói kérésre oldal betöltése | ❌ Nem | ✅ A ChatGPT-User crawler esetében igen |
A Googlebot elsődleges célja az indexelés
A Googlebot feladata, hogy feltérképezze az internetet, letöltse a weboldalakat, majd eldöntse, hogy azok bekerüljenek-e a Google indexébe.
Ezután a Google rangsorolási rendszerei számos tényező alapján értékelik az oldalakat, például:
- a tartalom minőségét;
- a keresési szándékot;
- a backlinkeket;
- a felhasználói élményt;
- a technikai SEO-t;
- az E-E-A-T jeleket.
Ha például valaki rákeres arra, hogy „hőszivattyú működése”, a Googlebot által feltérképezett és indexelt oldalak közül választja ki a Google a legrelevánsabb találatokat.
Az OpenAI crawlerek célja az AI rendszerek támogatása
Az OpenAI robotjai más szemlélettel dolgoznak. Nem az a céljuk, hogy több milliárd oldalas keresőindexet építsenek, hanem hogy támogassák az OpenAI különböző szolgáltatásait.
Például:
- az OAI-SearchBot segíti a ChatGPT Search működését;
- a ChatGPT-User egy felhasználó kérésére tölthet le egy konkrét weboldalt;
- a GPTBot nyilvános webes tartalmakat gyűjthet a jövőbeli AI modellek fejlesztéséhez.
Ezért egy OpenAI crawler látogatása nem feltétlenül jelenti azt, hogy az oldalad megjelenik egy hagyományos kereső találatai között.
Mindkettő figyeli a weboldal szerkezetét
Bár eltérő célból dolgoznak, számos közös elemet vizsgálnak.
Mind a Googlebot, mind az OpenAI crawlerei elemzik például:
- a H1–H6 címsorokat;
- a belső linkeket;
- a strukturált adatokat;
- a metaadatokat;
- a HTML szerkezetét;
- az oldal technikai állapotát.
Ezek az elemek segítenek a weboldal tartalmának értelmezésében.
A szemantikus értelmezés mindkét rendszerben fontos
Régen a keresőoptimalizálás nagyrészt a kulcsszavakról szólt. Ma már mind a Google, mind az AI rendszerek a jelentést próbálják megérteni.
Ezért egy modern weboldal esetében sokkal fontosabb:
- a témák részletes feldolgozása;
- az entitások egyértelmű használata;
- a logikus tartalomstruktúra;
- a kapcsolódó témák összekapcsolása;
- a hiteles források alkalmazása.
Ha például egy SEO weboldalon külön útmutató készül a technikai SEO-ról, a strukturált adatokról, a topical authority-ről, az AI Visibilityről és a belső linkelésről, akkor mind a Google, mind az OpenAI könnyebben felismeri, hogy az oldal átfogó szakmai tudással rendelkezik.
Más cél, de sok közös elv
A Googlebot és az OpenAI crawlerei tehát nem egymás versenytársai, hanem különböző feladatokra specializált rendszerek.
A Google célja, hogy a legjobb weboldalakat jelenítse meg a keresési találatok között. Az OpenAI célja pedig az, hogy mesterséges intelligenciával minél pontosabb, hasznosabb és megbízhatóbb válaszokat tudjon adni a felhasználóknak.
A jó hír az, hogy egy magas minőségű, jól strukturált weboldal mindkét rendszer számára előnyt jelent. Ha logikus címsorokat használsz, részletes tartalmat készítesz, megfelelő belső linkhálózatot építesz, strukturált adatokat alkalmazol és valódi szakértelmet mutatsz be, akkor egyszerre javíthatod az esélyeidet a hagyományos keresőkben és az AI-alapú keresések világában is.
Hogyan ellenőrizheted, hogy járt-e nálad az OpenAI crawler?
Ha szeretnéd megtudni, hogy az OpenAI valamelyik crawlere meglátogatta-e a weboldaladat, több lehetőséged is van. A legpontosabb módszer a szervernaplók (server logok) elemzése, de bizonyos esetekben a webanalitikai eszközök is hasznos információkat adhatnak. Fontos tudni, hogy nem minden OpenAI crawler jelenik meg ugyanúgy, ezért érdemes külön figyelni a GPTBot, az OAI-SearchBot és a ChatGPT-User forgalmára.
Szervernaplók (server logok) ellenőrzése
A legmegbízhatóbb módszer a webszerver naplófájljainak elemzése.
A szerver minden egyes látogatást rögzít, többek között:
- a látogatás időpontját;
- a kért URL-t;
- a válaszkódot (200, 301, 404 stb.);
- az IP-címet;
- a User-Agent azonosítót.
A User-Agent alapján könnyen megállapítható, hogy egy valódi látogató, egy Googlebot vagy éppen valamelyik OpenAI crawler kérte le az oldalt.
Ha saját VPS-t vagy dedikált szervert használsz, a logok általában az Apache vagy az Nginx naplóiban találhatók. Megosztott tárhely esetén a legtöbb szolgáltató cPanelen vagy saját kezelőfelületén is biztosít hozzáférést.
A User-Agent azonosítása
Az OpenAI robotjai saját User-Agent azonosítóval jelentkeznek be.
Leggyakrabban ezekkel találkozhatsz:
| User-Agent | Jelentése |
|---|---|
| GPTBot | Nyilvános tartalmak feltérképezése a jövőbeli AI modellek fejlesztéséhez. |
| OAI-SearchBot | A ChatGPT Search működését támogató crawler. |
| ChatGPT-User | Felhasználói kérésre tölti le egy adott weboldal tartalmát. |
| OAI-AdsBot | A ChatGPT hirdetési rendszerének céloldalait ellenőrzi. |
Ha ezek valamelyike megjelenik a szervernaplóban, akkor biztos lehetsz benne, hogy az adott OpenAI robot elérte a weboldalad valamelyik oldalát. Az OpenAI hivatalos dokumentációja közzéteszi a támogatott robotokat és azok azonosítóit.
Logelemző eszközök használata
Nagyobb weboldalak esetén nem érdemes kézzel átnézni a naplófájlokat.
Erre kiváló megoldások például:
- GoAccess
- AWStats
- Matomo Log Analytics
- Screaming Frog Log File Analyser
- Splunk
- Elastic Stack (ELK)
Ezek az eszközök képesek külön csoportosítani a keresőrobotokat, így néhány kattintással láthatod, hogy milyen AI crawlerek jártak az oldaladon.
Google Analytics és más analitikai rendszerek
A hagyományos crawlerek többsége nem futtat JavaScriptet, ezért a GPTBot vagy az OAI-SearchBot általában nem jelenik meg a Google Analytics látogatói között.
Viszont ha a ChatGPT Search-ből valódi felhasználók kattintanak át a weboldaladra, akkor ezek a látogatások már mérhetők. Az OpenAI szerint a ChatGPT Search-ből érkező hivatkozások automatikusan tartalmazzák az utm_source=chatgpt.com paramétert, így a forgalom elkülönítve is elemezhető például Google Analytics 4-ben.
Robots.txt fájl ellenőrzése
Ha egyetlen OpenAI crawler sem jelenik meg a naplóidban, érdemes megnézni a robots.txt fájlodat.
Lehetséges, hogy korábban letiltottad valamelyik robotot.
Például:
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /Ebben az esetben a robotok tiszteletben tartják a tiltást, és nem térképezik fel az oldalt. Fontos azonban, hogy a különböző OpenAI robotok külön szabályozhatók, ezért mindig ellenőrizd, melyik User-Agentre vonatkozik az adott beállítás.
IP-címek ellenőrzése
Haladó felhasználók számára lehetőség van az IP-címek vizsgálatára is.
Az OpenAI nyilvánosan közzéteszi az egyes crawlerekhez tartozó IP-tartományokat, így ellenőrizhető, hogy a naplóban szereplő kérés valóban egy hivatalos OpenAI robotból érkezett-e, nem pedig egy hamisított User-Agentből. Ez különösen nagy forgalmú vagy biztonságkritikus weboldalak esetén lehet hasznos.
Hogyan ellenőrizd gyorsan?
| Ellenőrzési módszer | Mit mutat meg? | Ajánlott? |
|---|---|---|
| Szervernaplók | A crawlerek minden látogatását és User-Agentjét. | ⭐⭐⭐⭐⭐ |
| User-Agent keresése | Megmutatja, hogy GPTBot, OAI-SearchBot vagy ChatGPT-User járt-e az oldalon. | ⭐⭐⭐⭐⭐ |
| Logelemző programok | Automatikusan összesítik a robotforgalmat. | ⭐⭐⭐⭐☆ |
| Google Analytics 4 | A ChatGPT Search-ből érkező valódi felhasználói forgalmat méri. | ⭐⭐⭐⭐☆ |
| Robots.txt ellenőrzése | Megmutatja, hogy nem tiltottad-e le a crawlereket. | ⭐⭐⭐⭐⭐ |
| IP-cím ellenőrzése | Igazolja, hogy valódi OpenAI robot érkezett. | ⭐⭐⭐⭐☆ |
Mit érdemes rendszeresen figyelni?
Ha szeretnéd növelni a weboldalad láthatóságát az AI-alapú keresésekben, érdemes havonta legalább egyszer átnézni a szervernaplókat. Figyeld, hogy megjelenik-e a GPTBot, az OAI-SearchBot vagy a ChatGPT-User, mely oldalakat keresik fel, milyen gyakran térnek vissza, és kapnak-e 200-as válaszkódot. Ezek az adatok segítenek felmérni, hogy az OpenAI rendszerei valóban hozzáférnek-e a tartalmaidhoz, illetve időben észreveheted a robots.txt, a tűzfal (WAF) vagy más technikai beállítások okozta problémákat.
Hogyan szabályozhatod az OpenAI crawler működését?
Az OpenAI egyik előnye, hogy átlátható módon lehetőséget biztosít a weboldal-tulajdonosok számára crawlereinek szabályozására. Nem kell teljesen átengedned vagy teljesen letiltanod minden robotot: eldöntheted, hogy mely OpenAI crawlerek férhetnek hozzá a weboldaladhoz, és melyek nem. Ezt elsősorban a robots.txt fájl segítségével teheted meg.
Ez azért fontos, mert a különböző OpenAI robotok eltérő feladatot látnak el. Lehet, hogy szeretnéd, ha a weboldalad megjelenne a ChatGPT Search találatai között, ugyanakkor nem szeretnéd, hogy a nyilvános tartalmad felhasználható legyen a jövőbeli AI modellek fejlesztéséhez. Az OpenAI robotjai külön szabályozhatók, így ezt könnyedén megteheted.
A robots.txt a legfontosabb szabályozási eszköz
Az OpenAI crawlerei – a Googlebothoz hasonlóan – figyelembe veszik a robots.txt fájlban található szabályokat.
Ez a fájl a weboldalad gyökérkönyvtárában található, például:
https://pelda.hu/robots.txtItt adhatod meg:
- mely robotokat engeded be;
- mely robotokat tiltod le;
- mely könyvtárakat szeretnéd elrejteni;
- mely részek legyenek minden crawler számára elérhetők.
Ez a legegyszerűbb és egyben hivatalosan támogatott módja az OpenAI crawlerek kezelésének.
Eldöntheted, melyik OpenAI crawler férjen hozzá
Nem kell minden OpenAI robotot ugyanúgy kezelned.
Például külön szabályozhatod:
- GPTBot
- OAI-SearchBot
- ChatGPT-User
- OAI-AdsBot
Ez nagy rugalmasságot biztosít.
Egy SEO szakértő például dönthet úgy, hogy:
- szeretné a ChatGPT Search-ben való megjelenést;
- viszont nem szeretné, hogy a GPTBot felhasználja a tartalmait a modellek fejlesztéséhez.
Mindkettő teljesen legitim döntés.
Mikor érdemes engedélyezni az OpenAI crawlereket?
Sok vállalkozás számára előnyös lehet az OpenAI robotjainak engedélyezése.
Például ha:
- szeretnél megjelenni a ChatGPT Search találatai között;
- fontos számodra az AI Visibility;
- hosszú távon AI-barát weboldalt építesz;
- szakértőként szeretnél ismertté válni;
- részletes tudásbázist építesz.
Ez különösen igaz például:
- SEO ügynökségekre;
- villanyszerelő vállalkozásokra;
- klímás cégekre;
- kertészeti szakoldalakra;
- menyasszonyi ruhaszalonokra.
Minél több hiteles tartalmad érhető el az AI rendszerek számára, annál nagyobb lehet az esélye annak, hogy a jövőben ajánlott forrásként jelenj meg.
Mikor lehet indokolt a tiltás?
Nem minden weboldal számára ideális minden crawler engedélyezése.
Bizonyos esetekben érdemes lehet korlátozni egyes robotokat.
Például:
- zárt előfizetéses tartalom esetén;
- belső vállalati dokumentációknál;
- fejlesztés alatt álló rendszereknél;
- tesztkörnyezeteknél;
- olyan oldalaknál, ahol a tartalom AI-felhasználását nem szeretnéd engedélyezni.
Fontos azonban tudni, hogy a robots.txt nem biztonsági megoldás, hanem egy iránymutatás a szabályosan működő crawlerek számára. Az érzékeny tartalmak védelmére mindig használj hitelesítést vagy megfelelő jogosultságkezelést.
A robots.txt mellett más tényezőkre is figyelj
A crawler működését nem kizárólag a robots.txt befolyásolja.
Érdemes odafigyelni például:
- a HTTP válaszkódokra;
- a 403-as tiltásokra;
- a tűzfal (WAF) szabályaira;
- az IP-alapú blokkolásokra;
- a CDN beállításaira.
Előfordulhat például, hogy a robots.txt engedélyezi a GPTBotot, de egy túl szigorú tűzfalszabály mégis blokkolja annak hozzáférését.
A döntés stratégiai kérdés
Sokan felteszik a kérdést:
„Érdemes letiltani a GPTBotot?”
Erre nincs minden weboldalra érvényes válasz.
Ha elsődleges célod:
- a minél nagyobb AI láthatóság;
- a szakértői márkaépítés;
- a ChatGPT-ben való megjelenés;
- az AI keresőkben való jelenlét,
akkor általában célszerű átgondoltan engedélyezni azokat a crawlereket, amelyek ezt támogatják.
Ha viszont a tartalmaid felhasználását nem szeretnéd engedélyezni AI modellek fejlesztésére, akkor dönthetsz úgy is, hogy csak a GPTBotot tiltod, miközben az OAI-SearchBotot továbbra is engedélyezed. Így a weboldalad továbbra is megjelenhet a ChatGPT Search találatai között, miközben a GPTBot nem fér hozzá a nyilvános tartalmaidhoz erre a célra.
Szabályozási lehetőségek áttekintése
| Lehetőség | Mire szolgál? | Mikor érdemes használni? |
|---|---|---|
| Robots.txt | Az OpenAI crawlerek engedélyezése vagy tiltása. | Ez az elsődleges és hivatalosan támogatott megoldás. |
| Külön User-Agent szabályok | Egyes OpenAI robotok eltérő kezelése. | Ha például csak a GPTBotot szeretnéd letiltani. |
| HTTP státuszkódok | Az oldal hozzáférhetőségének szabályozása. | Hibás vagy ideiglenesen nem elérhető oldalak esetén. |
| Tűzfal (WAF) | A robotforgalom technikai szűrése. | Nagy forgalmú vagy fokozott védelmet igénylő weboldalaknál. |
| Hitelesítés (login) | A nem nyilvános tartalmak védelme. | Előfizetéses vagy belső rendszereknél. |
A legjobb megközelítés a tudatos szabályozás
Az OpenAI crawlereit nem érdemes automatikusan engedélyezni vagy letiltani. A legjobb megoldás az, ha tudatosan döntesz az egyes robotok szerepe alapján. Gondold át, milyen célokat szeretnél elérni: fontos-e számodra a ChatGPT Search-ben való megjelenés, szeretnéd-e növelni az AI-láthatóságodat, vagy inkább korlátoznád bizonyos tartalmaid felhasználását.
Ha tisztában vagy azzal, hogy a GPTBot, az OAI-SearchBot, a ChatGPT-User és az OAI-AdsBot milyen feladatot lát el, sokkal könnyebben alakíthatsz ki olyan beállításokat, amelyek egyszerre szolgálják a weboldalad érdekeit és az AI-korszakra felkészített SEO-stratégiádat.
Robots.txt beállítások OpenAI crawlerekhez
A robots.txt fájl az egyik legegyszerűbb és leghatékonyabb eszköz arra, hogy szabályozd, mely OpenAI crawlerek férhetnek hozzá a weboldaladhoz. A fájl a domain gyökérkönyvtárában található (például: https://pelda.hu/robots.txt), és a szabályosan működő crawlerek – köztük az OpenAI robotjai – ezt olvassák el, mielőtt feltérképeznék az oldaladat. Az OpenAI hivatalosan is támogatja a robots.txt alapú szabályozást a GPTBot és az OAI-SearchBot esetében.
Fontos azonban tudni, hogy nem minden OpenAI crawler viselkedik ugyanúgy. A GPTBot és az OAI-SearchBot robots.txt alapján szabályozható, míg a ChatGPT-User felhasználói kezdeményezésre működik, ezért annak kezelése eltérő lehet az OpenAI dokumentációja szerint.
Mikor érdemes robots.txt szabályokat használni?
A robots.txt segítségével eldöntheted például, hogy:
- szeretnéd-e engedélyezni a GPTBot működését;
- megjelenhet-e a weboldalad a ChatGPT Search találatai között;
- bizonyos könyvtárakat kizársz a feltérképezésből;
- csak a nyilvános tartalmak legyenek elérhetők;
- a teszt- vagy adminfelületek rejtve maradjanak.
Ez különösen hasznos lehet nagy tartalmi weboldalak, webshopok vagy vállalati portálok esetében.
Gyakori robots.txt beállítások
| Cél | Robots.txt példa |
|---|---|
| GPTBot teljes tiltása | User-agent: GPTBotDisallow: / |
| GPTBot teljes engedélyezése | User-agent: GPTBotAllow: / |
| OAI-SearchBot engedélyezése | User-agent: OAI-SearchBotAllow: / |
| OAI-SearchBot tiltása | User-agent: OAI-SearchBotDisallow: / |
| Csak egy könyvtár tiltása | User-agent: GPTBotDisallow: /admin/ |
| Több könyvtár tiltása | User-agent: GPTBotDisallow: /admin/Disallow: /private/ |
GPTBot teljes tiltása
Ha nem szeretnéd, hogy a GPTBot hozzáférjen a nyilvánosan elérhető tartalmaidhoz a jövőbeli AI modellek fejlesztése céljából, használhatod az alábbi szabályt:
User-agent: GPTBot
Disallow: /Ebben az esetben a GPTBot nem térképezi fel a weboldalad egyetlen oldalát sem. Ez nem érinti automatikusan a ChatGPT Search működését, mert azt az OAI-SearchBot kezeli.
GPTBot engedélyezése
Ha szeretnéd, hogy a GPTBot hozzáférjen a nyilvános tartalmaidhoz, elegendő ezt megadni:
User-agent: GPTBot
Allow: /Amennyiben nincs külön tiltó szabály, a GPTBot egyébként is hozzáférhet a nyilvánosan elérhető oldalakhoz.
OAI-SearchBot engedélyezése
Ha azt szeretnéd, hogy a weboldalad bekerülhessen a ChatGPT Search találatai közé, engedélyezheted az OAI-SearchBot számára a teljes webhelyet:
User-agent: OAI-SearchBot
Allow: /Ez különösen ajánlott olyan weboldalaknál, amelyek célja az AI-alapú keresésekből érkező látogatók megszerzése.
OAI-SearchBot tiltása
Ha nem szeretnéd, hogy az oldalad megjelenjen a ChatGPT Search keresési találatai között, ezt a szabályt használhatod:
User-agent: OAI-SearchBot
Disallow: /A Google keresési helyezéseidet ez nem befolyásolja, mert ez kizárólag az OpenAI keresőrobotjára vonatkozik.
Csak bizonyos könyvtárak tiltása
Nem feltétlenül kell az egész weboldalt letiltanod.
Például kizárhatod:
- az adminisztrációs felületet;
- a belső dokumentációt;
- a tesztoldalakat;
- az ügyfélfelületeket.
Példa:
User-agent: GPTBot
Disallow: /admin/
Disallow: /ugyfel/
Disallow: /teszt/Így a nyilvános blogbejegyzések továbbra is elérhetők maradnak.
Több OpenAI crawler egyidejű kezelése
A robots.txt egyik nagy előnye, hogy minden crawler külön szabályozható.
Például:
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: *
Allow: /Ebben a példában:
- a GPTBot nem fér hozzá a weboldalhoz;
- az OAI-SearchBot teljes hozzáférést kap;
- minden más robot is elérheti az oldalt.
Ez az egyik leggyakoribb beállítás azoknál a weboldalaknál, amelyek szeretnének megjelenni a ChatGPT Search-ben, de nem kívánják engedélyezni a GPTBot hozzáférését a modellfejlesztési célokra.
Érdemes rendszeresen ellenőrizni a beállításokat
Egy hibás robots.txt fájl komoly következményekkel járhat. Egyetlen elírás vagy túl általános szabály miatt előfordulhat, hogy nemcsak az OpenAI crawlereit, hanem más fontos robotokat is akaratlanul letiltod.
Minden módosítás után érdemes:
- ellenőrizni a robots.txt fájlt böngészőből;
- figyelni a szervernaplókat;
- megnézni, hogy az OpenAI crawlerei kapnak-e 200-as válaszkódot;
- ellenőrizni, hogy a tűzfal vagy a CDN nem blokkolja-e a robotokat.
A robots.txt önmagában csak az első lépés. Ha azt szeretnéd, hogy a weboldalad valóban jól teljesítsen az AI-alapú keresésekben, a megfelelő hozzáférés mellett minőségi tartalomra, jól felépített belső linkhálózatra, strukturált adatokra és egyértelmű szemantikus kapcsolatokra is szükség lesz.
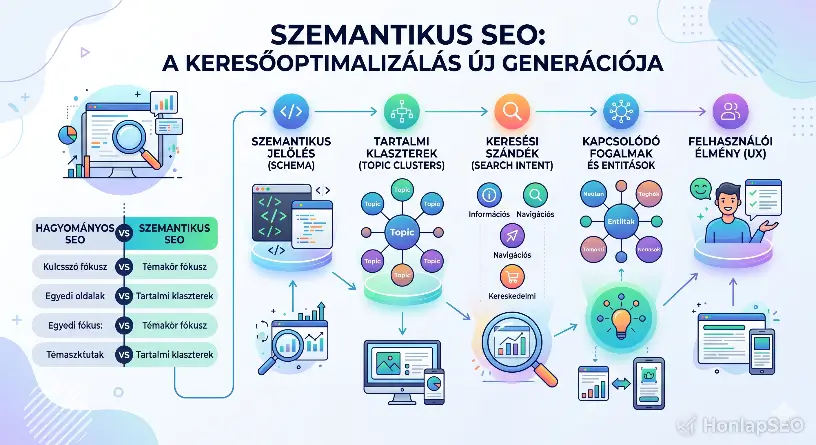
Mit jelent mindez SEO és AI keresőoptimalizálás szempontjából?
Az OpenAI crawlereinek megjelenése jól mutatja, hogy a keresés világa jelentős átalakuláson megy keresztül. Korábban szinte kizárólag a Google robotjaira kellett figyelni, ma azonban egyre több mesterséges intelligencia alapú rendszer térképezi fel a webet. Ez nem jelenti azt, hogy a hagyományos SEO elveszítette volna a jelentőségét, de azt igen, hogy a keresőoptimalizálás kiegészült egy új szemlélettel: az AI keresőoptimalizálással (AI SEO, GEO vagy AEO).
A jó hír az, hogy a klasszikus SEO alapelvei továbbra is működnek. A különbség inkább abban rejlik, hogy az AI rendszerek még nagyobb hangsúlyt fektetnek a tartalom jelentésére, a szakmai hitelességre és az összefüggések megértésére, nem pedig pusztán a kulcsszavak előfordulására.
Az AI nem kulcsszavakat, hanem jelentést keres
Régen elegendő volt egy kulcsszót többször elhelyezni egy oldalon ahhoz, hogy a Google könnyebben felismerje a témát. Ma már sem a Google, sem az OpenAI rendszerei nem így működnek.
Egy modern AI crawler azt próbálja megérteni:
- miről szól valójában az oldal;
- milyen kérdésekre ad választ;
- mennyire részletes a tartalom;
- milyen fogalmak kapcsolódnak egymáshoz;
- mennyire hiteles az információ.
Ha például egy cikk csak felszínesen ír a hőszivattyúkról, kevés esélye lesz arra, hogy szakértői forrásként tekintsenek rá. Ezzel szemben egy részletes útmutató, amely bemutatja a működést, a telepítést, a költségeket, a karbantartást és a gyakori hibákat, sokkal értékesebb tudásforrást jelent.
A topical authority szerepe még fontosabb lett
Az AI rendszerek nemcsak egyetlen cikket vizsgálnak, hanem azt is, hogy mennyire mélyen dolgoz fel egy weboldal egy adott témát.
Ez az úgynevezett topical authority, vagyis témaköri szakértelem.
Például egy SEO weboldal akkor épít erős topical authorityt, ha nem csupán egyetlen cikket ír a keresőoptimalizálásról, hanem részletes útmutatókat készít többek között:
- technikai SEO-ról;
- linképítésről;
- strukturált adatokról;
- AI keresőoptimalizálásról;
- kulcsszókutatásról;
- belső linkelésről;
- AI Visibilityről.
Ugyanez igaz más területekre is.
Egy kertészeti weboldalon érdemes külön tartalmat készíteni a növénygondozásról, öntözésről, metszésről, növényvédelemről és talajjavításról. Egy villanyszerelő oldalán a hálózatbővítés, a Fi-relé, a biztosítéktábla vagy az érintésvédelem külön cikkekben való bemutatása segíthet bizonyítani a szakértelmet.
Az entitások egyre nagyobb szerepet kapnak
Az OpenAI crawlerei nem csupán kulcsszavakat azonosítanak, hanem entitásokat is.
Ilyenek lehetnek:
- személyek;
- cégek;
- márkák;
- termékek;
- szolgáltatások;
- földrajzi helyek.
Minél egyértelműbben jelennek meg ezek a weboldaladon, annál könnyebben tudja az AI megérteni, hogy pontosan kiről vagy miről szól a tartalom.
Ezért fontos például:
- következetesen használni a vállalkozás nevét;
- részletes szerzői profilokat készíteni;
- strukturált adatokat alkalmazni;
- egységes márkakommunikációt kialakítani.
A strukturált adatok segítik az AI értelmezését
A Schema.org strukturált adatok ma már nemcsak a Google számára hasznosak.
Az AI rendszerek számára is egyértelmű információkat adnak arról, hogy:
- ki a szerző;
- milyen szolgáltatásról van szó;
- melyik vállalkozás üzemelteti az oldalt;
- mikor készült a cikk;
- milyen kérdésekre válaszol.
Egy megfelelően felépített strukturált adat jelentősen megkönnyítheti a weboldal tartalmának értelmezését.
A hitelesség fontosabb, mint valaha
Az AI rendszerek célja, hogy megbízható válaszokat adjanak.
Ezért nagy jelentősége van annak, hogy egy weboldal:
- valódi szakértelmet mutasson;
- naprakész legyen;
- pontos információkat tartalmazzon;
- következetesen építse a márkáját;
- hivatkozzon hiteles forrásokra.
Egy klímás vállalkozás például sokkal hitelesebbnek tűnik, ha nemcsak szolgáltatásokat sorol fel, hanem részletes útmutatókat is készít a hőszivattyúk működéséről, a karbantartásról és az energiahatékonyságról.
Az AI keresőoptimalizálás nem váltja ki a SEO-t
Sokan úgy gondolják, hogy az AI megjelenésével a SEO háttérbe szorul.
Valójában ennek éppen az ellenkezője történik.
A jól felépített SEO ma már az AI rendszerek számára is előnyt jelent.
Ha a weboldalad:
- gyors;
- mobilbarát;
- logikusan strukturált;
- részletes tartalmakat tartalmaz;
- jól felépített belső linkhálózattal rendelkezik;
- strukturált adatokat használ;
- erős topical authorityt épít,
akkor egyszerre javíthatod a láthatóságodat a Google-ben és az AI-alapú keresésekben is.
SEO és AI keresőoptimalizálás kéz a kézben jár
| SEO elem | Miért fontos az AI számára? |
|---|---|
| Részletes tartalom | Segíti a témák mélyebb megértését. |
| Topical authority | Bizonyítja a szakmai kompetenciát egy adott területen. |
| Belső linkelés | Feltárja a témák közötti kapcsolatokat. |
| Strukturált adatok | Egyértelmű információkat adnak az AI rendszereknek. |
| Entitások | Segítik a személyek, cégek és szolgáltatások azonosítását. |
| E-E-A-T jelek | Növelik a tartalom hitelességét és megbízhatóságát. |
| Frissített tartalom | Az AI számára is értékesebb és naprakészebb információforrás. |
| Technikai SEO | Könnyebbé teszi a crawlerek számára az oldal feldolgozását. |
A jövő a szemantikus tartalomé
Az OpenAI crawlerei egyértelműen jelzik, hogy a jövő keresőoptimalizálása már nem kizárólag a rangsorolásról, hanem a megértésről szól. Az AI rendszerek azt keresik, hogy mely weboldalak adnak átfogó, hiteles és jól strukturált válaszokat egy adott témára.
Ezért ma már nem elegendő néhány kulcsszóra optimalizálni egy oldalt. Sokkal fontosabb teljes tudásbázisokat építeni, összekapcsolni a kapcsolódó témákat, egyértelmű entitásokat használni és valódi szakértelmet bemutatni. Azok a weboldalak, amelyek ezt a szemléletet követik, nemcsak a hagyományos keresőkben, hanem az AI-alapú keresések világában is jelentős versenyelőnyre tehetnek szert.
Hogyan optimalizáld a weboldalad az OpenAI számára?
Bár az OpenAI nem közöl hivatalos rangsorolási algoritmust, a crawlereinek működése és az AI rendszerek szemantikus tartalomértelmezése alapján jól látható, milyen tulajdonságokkal rendelkező weboldalak teljesítenek jobban. Az alapelv egyszerű: ne az AI-nak írj, hanem olyan tartalmat készíts, amelyet az AI könnyen megért, hitelesnek értékel és összefüggéseiben is képes értelmezni.
Ha szeretnéd növelni annak esélyét, hogy a weboldalad megjelenjen a ChatGPT Search-ben vagy más AI-alapú keresők válaszaiban, akkor nem egyetlen trükkre van szükség, hanem egy tudatos, hosszú távú tartalomstratégiára.
Építs teljes témaklasztereket
Az AI rendszerek nem csupán egyetlen cikket értékelnek, hanem azt is vizsgálják, hogy mennyire mélyen dolgozol fel egy adott témát.
Ezért érdemes egy fő témát több kapcsolódó cikkre bontani.
Például egy SEO weboldalon külön útmutató készülhet:
- technikai SEO-ról;
- kulcsszókutatásról;
- belső linkelésről;
- strukturált adatokról;
- AI SEO-ról;
- linképítésről;
- topical authority-ről;
- AI Visibility-ről.
Ugyanez működik más területeken is. Egy kertészeti weboldalon a metszés, a talajjavítás, az öntözés és a növényvédelem külön cikkekben való feldolgozása sokkal erősebb szakmai képet mutat, mint egyetlen általános útmutató.
Készíts részletes, valódi szakmai tartalmat
Az OpenAI rendszerei a rövid, felületes cikkek helyett azokat az oldalakat értékelik jobban, amelyek valóban megválaszolják a felhasználók kérdéseit.
Érdemes:
- részletes magyarázatokat adni;
- gyakorlati példákat használni;
- összehasonlításokat készíteni;
- táblázatokkal segíteni az áttekinthetőséget;
- valós tapasztalatokat bemutatni.
Például egy villanyszerelő weboldalon ne csak azt írd le, hogy mi az a Fi-relé, hanem mutasd be azt is, hogyan működik, mikor kell cserélni, milyen hibák fordulnak elő és mire kell figyelni a kiválasztásakor.
Használj logikus címsorstruktúrát
A jól felépített H1–H2–H3 hierarchia nemcsak az olvasóknak segít, hanem az AI crawlereknek is.
Egy logikus szerkezetből gyorsan megérthető:
- mi a fő téma;
- milyen kérdésekre válaszol a cikk;
- hogyan kapcsolódnak egymáshoz az alfejezetek.
Ez különösen fontos hosszabb útmutatóknál.
Alkalmazz strukturált adatokat
A Schema.org jelölések segítenek az AI rendszereknek egyértelműen értelmezni a weboldalad tartalmát.
Érdemes használni többek között:
- Article
- FAQPage
- Organization
- Person
- LocalBusiness
- Service
- Product
- BreadcrumbList
A strukturált adatok nem helyettesítik a jó tartalmat, de jelentősen megkönnyítik annak értelmezését.
Építs erős belső linkhálózatot
A belső linkelés nemcsak SEO szempontból fontos.
Segítségével az AI rendszerek is könnyebben felismerik:
- mely cikkek kapcsolódnak egymáshoz;
- melyik a fő tartalom;
- milyen témák alkotnak tudásbázist.
Például egy „Hőszivattyú működése” című cikkből természetes módon hivatkozhatsz:
- a telepítésről szóló útmutatóra;
- a karbantartásra;
- az energiafogyasztásra;
- a levegő-víz hőszivattyúk összehasonlítására.
Építs egyértelmű entitásokat
Az AI rendszerek számára fontos, hogy könnyen felismerhető legyen:
- ki a szerző;
- melyik vállalkozás áll a weboldal mögött;
- milyen szolgáltatásokat nyújtasz;
- milyen márkához kapcsolódik a tartalom.
Ezért érdemes következetesen használni:
- a vállalkozás nevét;
- a szerző nevét;
- az „Rólunk” oldalt;
- a kapcsolatfelvételi adatokat;
- a megfelelő strukturált adatokat.
Frissítsd rendszeresen a tartalmaidat
Az AI rendszerek számára is értékesebbek azok a weboldalak, amelyek folyamatosan fejlődnek.
Érdemes:
- frissíteni a statisztikákat;
- új példákat hozzáadni;
- bővíteni a GYIK részt;
- aktualizálni a képernyőképeket;
- javítani az elavult információkat.
Egy három éve változatlan cikk általában kevésbé értékes, mint egy rendszeresen karbantartott útmutató.
Figyelj a technikai SEO-ra
A legjobb tartalom sem ér sokat, ha a crawler nehezen tudja feldolgozni.
Ezért fontos:
- gyors oldalbetöltés;
- HTTPS használata;
- mobilbarát kialakítás;
- hibamentes HTML;
- megfelelő canonical címkék;
- XML sitemap;
- helyes robots.txt beállítás.
A technikai SEO biztosítja, hogy az OpenAI crawlerei könnyen hozzáférjenek a tartalmaidhoz.
Gondolkodj a felhasználó fejével
Az AI rendszerek célja ugyanaz, mint a keresőmotoroké: a lehető legjobb választ adni a felhasználó kérdésére.
Ezért minden cikk írásakor érdemes feltenned magadnak a kérdést:
- Valóban megválaszolja a felhasználó problémáját?
- Van benne gyakorlati példa?
- Könnyen áttekinthető?
- Hiányzik belőle valamilyen fontos információ?
Ha a válasz igen, jó úton jársz.
OpenAI-optimalizálási ellenőrző lista
| Optimalizálás | Miért fontos? |
|---|---|
| Topical authority építése | Bizonyítja a mély szakértelmet egy adott témában. |
| Részletes, minőségi tartalom | Az AI könnyebben talál átfogó válaszokat. |
| Logikus címsorstruktúra | Segíti a tartalom értelmezését. |
| Schema.org strukturált adatok | Egyértelmű információkat adnak az AI számára. |
| Belső linkelés | Megmutatja a témák közötti kapcsolatokat. |
| FAQ szekciók | Közvetlen válaszokat adnak gyakori kérdésekre. |
| Egyértelmű entitások | Segítik a szerzők, cégek és szolgáltatások azonosítását. |
| Szerzői profilok | Erősítik a hitelességet és a szakértelmet. |
| Rendszeres tartalomfrissítés | Naprakészen tartja a weboldalt. |
| Gyors, mobilbarát weboldal | Megkönnyíti a crawlerek és a felhasználók számára is az oldal használatát. |
| Technikai SEO | Biztosítja a hibamentes feltérképezést. |
| Robots.txt megfelelő beállítása | Szabályozza az OpenAI crawlereinek hozzáférését. |
Az AI számára a minőség a legfontosabb
Az OpenAI crawlerei nem keresnek különleges optimalizálási trükköket vagy titkos beállításokat. Azt próbálják megállapítani, hogy egy weboldal mennyire hasznos, hiteles és könnyen értelmezhető. Éppen ezért a legjobb stratégia továbbra is az, hogy valódi értéket teremtesz az olvasóknak.
Ha részletes témaklasztereket építesz, logikusan strukturálod a tartalmaidat, alkalmazod a strukturált adatokat, rendszeresen frissíted az útmutatóidat, és következetesen építed a szakértői márkádat, akkor nemcsak a Google, hanem az OpenAI és más AI-alapú keresőrendszerek számára is egyre értékesebb információforrássá válhat a weboldalad.
Milyen hibákat követnek el a legtöbben?
Ahogy egyre több vállalkozás kezd foglalkozni az AI keresőoptimalizálással, egyre több tévhit és rossz gyakorlat is megjelenik. Sokan még mindig kizárólag a hagyományos SEO szemléletével gondolkodnak, miközben az OpenAI crawlerei és más AI rendszerek jóval összetettebben értelmezik a weboldalakat. Ennek következtében gyakran olyan hibák fordulnak elő, amelyek nemcsak az AI láthatóságot csökkentik, hanem a felhasználói élményt is rontják.
Az alábbi hibák a leggyakoribbak, amelyeket érdemes elkerülnöd.
Csak a Google-re optimalizálnak
Sok weboldal-tulajdonos még mindig úgy gondolja, hogy ha a Google-ben jó helyezést ér el, akkor automatikusan az AI rendszerek is előnyben részesítik.
Ez részben igaz, de nem teljesen.
Az AI rendszerek sokkal nagyobb hangsúlyt fektetnek:
- a szemantikus összefüggésekre;
- a témák teljes körű feldolgozására;
- az entitásokra;
- a szakmai hitelességre.
Ezért ma már nem elég néhány kulcsszóra optimalizált cikket írni.
Felületes tartalmak készítése
Az egyik leggyakoribb hiba, hogy valaki nagyon rövid cikkekkel próbál minden kulcsszót lefedni.
Például:
- „Mi az a hőszivattyú?” – 300 szó.
- „Mi az a Fi-relé?” – 250 szó.
- „SEO jelentése.” – 200 szó.
Az AI rendszerek ehelyett azokat a tartalmakat részesítik előnyben, amelyek valóban körbejárják a témát, válaszolnak a kapcsolódó kérdésekre és gyakorlati példákat is bemutatnak.
Nincs topical authority
Sokan egyetlen cikket írnak egy témáról, majd azt várják, hogy szakértőként tekintsen rájuk az AI.
Pedig a szakértelmet nem egyetlen oldal bizonyítja.
Ha például villanyszereléssel foglalkozol, érdemes külön tartalmat készíteni:
- a Fi-reléről;
- a kismegszakítókról;
- az érintésvédelemről;
- a hálózatbővítésről;
- a vezetékek színeiről;
- az EPH rendszerről.
Minél mélyebben dolgozol fel egy témát, annál könnyebben felismeri ezt az AI.
Gyenge belső linkelés
Sok weboldalon a cikkek teljesen elszigetelten léteznek.
Nincs kapcsolat közöttük.
Pedig a belső linkek segítenek:
- a témák összekapcsolásában;
- a tudásbázis felépítésében;
- a crawlerek tájékozódásában.
Ha például írsz egy cikket a hőszivattyú működéséről, természetes, hogy abból linkelsz a telepítésről, a karbantartásról és az energiafogyasztásról szóló útmutatókra.
A strukturált adatok mellőzése
Sokan még ma sem használnak Schema.org jelöléseket.
Pedig ezek segítenek az AI számára egyértelműen azonosítani:
- a szerzőt;
- a vállalkozást;
- a szolgáltatást;
- a cikk típusát;
- a GYIK részt.
A strukturált adatok ugyan nem helyettesítik a jó tartalmat, de jelentősen megkönnyítik annak értelmezését.
Hiányoznak a szerzői információk
Egy névtelen cikk sokkal kevésbé hiteles, mint egy olyan tartalom, amely mögött valódi szakember áll.
Érdemes feltüntetni:
- a szerző nevét;
- rövid bemutatkozását;
- szakmai tapasztalatát;
- elérhetőségét;
- kapcsolódó közösségi profiljait vagy szakmai oldalait.
Ez nemcsak az olvasóknak, hanem az AI rendszereknek is segít a hitelesség megítélésében.
Elavult tartalmak
Sokan elkészítenek egy cikket, majd évekig nem nyúlnak hozzá.
Pedig közben:
- új technológiák jelennek meg;
- változnak a Google ajánlásai;
- fejlődnek az AI keresők;
- új szabványok születnek.
A rendszeresen frissített tartalmak sokkal értékesebbek, mint a régen publikált, elavult útmutatók.
Hibás robots.txt beállítások
Meglepően gyakori, hogy valaki véletlenül letiltja az OpenAI crawlereit.
Például:
- rossz User-Agent használata;
- túl általános
Disallowszabály; - teljes webhely tiltása.
Ez azt eredményezheti, hogy az AI rendszerek egyszerűen nem férnek hozzá a tartalmaidhoz.
Gyenge technikai SEO
Hiába kiváló a tartalom, ha a weboldal technikai problémákkal küzd.
Például:
- lassú betöltés;
- hibás átirányítások;
- sok 404-es oldal;
- hiányzó HTTPS;
- hibás canonical címkék;
- rossz mobilos megjelenés.
Ezek a problémák megnehezíthetik a crawlerek munkáját is.
AI-val generált, de nem szerkesztett tartalom
Az egyik legújabb hiba, hogy valaki teljes egészében AI-val készíttet cikkeket, majd változtatás nélkül közzéteszi őket.
Az ilyen tartalmak gyakran:
- ismétlődnek;
- túl általánosak;
- kevés saját tapasztalatot tartalmaznak;
- nem válaszolják meg mélyen a felhasználók kérdéseit.
Az AI kiváló segítség lehet a tartalomkészítésben, de a valódi szakmai tudást, az egyedi példákat és a személyes tapasztalatokat nem helyettesíti.
A leggyakoribb hibák összefoglalása
| Gyakori hiba | Miért probléma? | Mit érdemes helyette tenni? |
|---|---|---|
| Csak a Google-re optimalizálsz | Figyelmen kívül hagyod az AI rendszerek eltérő működését. | Gondolkodj szemantikusan és AI-barát struktúrában. |
| Rövid, felületes cikkeket írsz | Kevés információt adnak az AI és az olvasók számára. | Készíts részletes, átfogó útmutatókat. |
| Nincs topical authority | Nem alakul ki szakértői kép egy témában. | Építs témaklasztereket és tudásbázist. |
| Gyenge belső linkelés | A tartalmak elszigeteltek maradnak. | Kösd össze a kapcsolódó cikkeket. |
| Hiányoznak a strukturált adatok | Az AI nehezebben értelmezi az oldalt. | Használj Schema.org jelöléseket. |
| Nincs szerző vagy céginformáció | Csökkenhet a hitelesség. | Mutasd be a szerzőt és a vállalkozást. |
| Nem frissíted a tartalmat | Az információk elavulhatnak. | Rendszeresen aktualizáld a cikkeket. |
| Hibás robots.txt | Az OpenAI crawlerei nem férnek hozzá az oldalhoz. | Rendszeresen ellenőrizd a beállításokat. |
| Gyenge technikai SEO | Lassítja vagy akadályozza a feltérképezést. | Javítsd a technikai hibákat és optimalizáld az oldalt. |
| Szerkesztés nélküli AI-tartalom | Általános, ismétlődő és kevésbé hiteles lehet. | Egészítsd ki saját tapasztalatokkal és szakmai példákkal. |
A legnagyobb hiba: csak a robotokra gondolni
Sokan úgy tekintenek az AI keresőoptimalizálásra, mintha kizárólag a crawlereknek kellene megfelelni. Ez téves megközelítés. Az OpenAI rendszereinek végső célja ugyanaz, mint a Google-é: a felhasználók számára a lehető legjobb választ megtalálni.
Ha olyan tartalmat készítesz, amely valóban segít az embereknek, logikusan felépített, naprakész, részletes és hiteles, akkor egyszerre javítod az esélyeidet a hagyományos keresőkben és az AI-alapú keresésekben is. A hosszú távú siker kulcsa nem a robotok „kijátszása”, hanem a valódi szakmai érték megteremtése.
OpenAI crawler ellenőrző lista
Ha szeretnéd, hogy a weboldalad könnyen feltérképezhető és értelmezhető legyen az OpenAI crawlerei számára, érdemes időről időre végigmenned egy ellenőrző listán. Ez segít kiszűrni azokat a technikai és tartalmi hibákat, amelyek akadályozhatják az AI rendszerek munkáját, miközben a hagyományos SEO teljesítményét is javíthatják.
Az alábbi lista nemcsak a GPTBot vagy az OAI-SearchBot működését veszi figyelembe, hanem azokat a szempontokat is, amelyek hozzájárulnak ahhoz, hogy a weboldalad hiteles, jól strukturált és AI-barát legyen.
OpenAI crawler ellenőrző lista
| Ellenőrzési pont | Rendben? |
|---|---|
| A robots.txt fájl elérhető és hibamentes. | ☐ |
| A kívánt OpenAI crawlerek (GPTBot, OAI-SearchBot) megfelelően vannak engedélyezve vagy tiltva. | ☐ |
| A weboldal HTTPS kapcsolaton érhető el. | ☐ |
| Nincs olyan tűzfal (WAF) vagy CDN-beállítás, amely véletlenül blokkolja az OpenAI robotjait. | ☐ |
| A fontos oldalak nem kapnak 404-es vagy 500-as hibát. | ☐ |
| A szervernaplókban megjelennek az OpenAI crawlerek látogatásai. | ☐ |
| A weboldal rendelkezik XML sitemap fájllal. | ☐ |
| A fontos oldalak szerepelnek a sitemapban. | ☐ |
| Minden oldalnak egyértelmű H1 címe van. | ☐ |
| A H2 és H3 címsorok logikusan épülnek egymásra. | ☐ |
| A tartalom részletesen feldolgozza a témát. | ☐ |
| A kapcsolódó cikkek belső linkekkel össze vannak kötve. | ☐ |
| A weboldalon témaklaszterek (Topical Authority) épülnek. | ☐ |
| Használsz Schema.org strukturált adatokat. | ☐ |
| A szerző és a vállalkozás egyértelműen azonosítható. | ☐ |
| A cikkek rendszeresen frissülnek. | ☐ |
| A képek rendelkeznek beszédes ALT szöveggel. | ☐ |
| A meta title és meta description minden fontos oldalon egyedi. | ☐ |
| A weboldal gyorsan betöltődik mobilon és asztali gépen is. | ☐ |
| A tartalom valódi szakmai tapasztalatot és gyakorlati példákat is tartalmaz. | ☐ |
Mit érdemes havonta ellenőrizni?
Nem minden ellenőrzési pont igényel napi figyelmet, de néhányat érdemes rendszeresen átnézni.
Legalább havonta egyszer ellenőrizd:
- a szervernaplókat;
- a robots.txt fájlt;
- a sitemap frissességét;
- az újonnan megjelent hibás oldalak számát;
- a frissítendő cikkeket;
- a belső linkhálózat bővítésének lehetőségeit.
Ha rendszeresen publikálsz új tartalmat, célszerű azt is megnézni, hogy az új cikkek megfelelően kapcsolódnak-e a meglévő tudásbázishoz.
Mikor érdemes teljes AI SEO auditot végezni?
Az ellenőrző lista kiváló gyors áttekintésre, de bizonyos esetekben ennél részletesebb vizsgálatra is szükség lehet.
Érdemes teljes AI SEO auditot készíteni:
- új weboldal indulásakor;
- nagyobb weboldal-átalakítás után;
- domainváltás esetén;
- jelentős tartalomfrissítést követően;
- ha szeretnél nagyobb láthatóságot elérni a ChatGPT Search-ben vagy más AI-alapú keresőkben.
Ilyenkor nemcsak a crawlerek hozzáférését vizsgálod, hanem a tartalom minőségét, a témaklasztereket, az entitásokat, a strukturált adatokat és a technikai SEO elemeit is.
Az ellenőrző lista csak az első lépés
Az OpenAI crawlerei számára megfelelően beállított weboldal még önmagában nem garantálja, hogy tartalmad megjelenik az AI-alapú válaszokban. A robots.txt, a technikai SEO és a strukturált adatok csupán az alapokat teremtik meg.
A valódi versenyelőnyt továbbra is az adja, ha mély szakmai tudásra épülő tartalmakat készítesz, logikus témaklasztereket alakítasz ki, rendszeresen frissíted a cikkeidet, és következetesen építed a digitális hitelességedet. Ha ezekre is odafigyelsz, az ellenőrző lista nemcsak kipipált feladatok gyűjteménye lesz, hanem egy olyan stratégia része, amely hosszú távon segítheti a weboldalad sikerét a Google-ben és az AI-alapú keresések világában egyaránt.
Összegzés
Az OpenAI crawlerei új fejezetet nyitottak a weboldalak feltérképezésében. Míg korábban szinte kizárólag a Googlebot működésére kellett figyelni, ma már egyre fontosabb megérteni azt is, hogyan dolgoznak az AI rendszerek, milyen információkat gyűjtenek, és hogyan értelmezik a weboldalak tartalmát. Ez azonban nem azt jelenti, hogy teljesen új szabályok szerint kellene weboldalt építened. Sokkal inkább arról van szó, hogy a hagyományos SEO alapjai kibővültek egy szemantikus, AI-központú megközelítéssel.
Ebben az útmutatóban végigvettük, hogy mik azok az OpenAI crawlerek, milyen feladatot látnak el, hogyan működnek, milyen adatokat dolgoznak fel, hogyan ellenőrizheted a látogatásaikat, és miként szabályozhatod a hozzáférésüket a robots.txt fájl segítségével. Azt is láthattad, hogy az OpenAI robotjai nem egyszerűen kulcsszavakat keresnek, hanem a weboldal teljes szerkezetét, a témák közötti kapcsolatokat, az entitásokat és a szakmai hitelességet is igyekeznek megérteni.
Az AI keresőoptimalizálás alapja továbbra is a minőségi, részletes és jól strukturált tartalom. Ha logikus címsorokat használsz, témaklasztereket építesz, megfelelő belső linkhálózatot alakítasz ki, strukturált adatokat alkalmazol, és rendszeresen frissíted a tartalmaidat, akkor nemcsak a hagyományos keresők, hanem az AI-alapú rendszerek számára is könnyebben értelmezhetővé válik a weboldalad.
Fontos azonban szem előtt tartani, hogy nincs külön „OpenAI SEO-trükk”, amely önmagában sikerre vezetne. Az AI rendszerek elsődleges célja ugyanaz, mint a keresőmotoroké: a felhasználók számára a lehető legjobb, legpontosabb és legmegbízhatóbb választ megtalálni. Éppen ezért hosszú távon azok a weboldalak kerülhetnek előnybe, amelyek valódi szakértelmet mutatnak be, hiteles információkat közölnek, és egy adott témát teljes mélységében dolgoznak fel.
Ha most kezded felkészíteni a weboldaladat az AI korszakára, érdemes elsőként átnézned a robots.txt beállításaidat, ellenőrizni a strukturált adatokat, fejleszteni a belső linkelést, majd tudatosan építeni a topical authorityt. Ezek azok az alapok, amelyek nemcsak az OpenAI crawlerei, hanem más AI-alapú keresők és válaszmotorok számára is értékesebbé teszik a weboldaladat.
Az AI-alapú keresés még folyamatosan fejlődik, de egy dolog már most biztos: a jövő nyertesei azok lesznek, akik nem a robotokat próbálják kijátszani, hanem olyan tartalmat készítenek, amely valódi értéket nyújt az embereknek. Ha erre építed a tartalomstratégiádat, akkor a weboldalad jó eséllyel nemcsak a Google-ben, hanem a mesterséges intelligencia által támogatott keresésekben is egyre nagyobb láthatóságot érhet el.
GYIK ❓
Mi az az OpenAI crawler?
Az OpenAI crawler egy automatikus webes robot, amely nyilvánosan elérhető weboldalakat látogat meg és dolgoz fel különböző célokra. Az OpenAI többféle crawlert használ, például a GPTBotot, az OAI-SearchBotot vagy a ChatGPT-User robotot, amelyek eltérő feladatokat látnak el. Egyesek az AI modellek fejlesztését támogatják, mások a ChatGPT keresési funkcióját vagy a felhasználók által kért weboldalak feldolgozását segítik.
Miben különbözik a GPTBot és az OAI-SearchBot?
A GPTBot elsődleges feladata a nyilvánosan elérhető webes tartalmak feltérképezése az OpenAI jövőbeli AI modelljeinek fejlesztéséhez. Az OAI-SearchBot ezzel szemben a ChatGPT Search működését támogatja, vagyis azt segíti elő, hogy egy weboldal megjelenhessen a ChatGPT keresési találatai között. A két crawler külön-külön szabályozható a robots.txt fájlban.
Mi az a ChatGPT-User?
A ChatGPT-User egy speciális User-Agent, amely akkor jelenik meg, amikor egy felhasználó arra kéri a ChatGPT-t, hogy nyisson meg, elemezzen vagy foglaljon össze egy konkrét weboldalt. Ez nem folyamatos webes feltérképezést végez, hanem kizárólag felhasználói kérésre tölti le az adott oldal tartalmát.
Be kell engednem az OpenAI crawlereit?
Nem kötelező. A döntés teljes mértékben a weboldal tulajdonosán múlik. Ha szeretnéd növelni az esélyét annak, hogy a weboldalad megjelenjen a ChatGPT Search találatai között, érdemes engedélyezni az OAI-SearchBot működését. Ha viszont nem szeretnéd, hogy a nyilvános tartalmad AI modellek fejlesztéséhez felhasználható legyen, letilthatod a GPTBotot.
Hogyan tilthatom le az OpenAI crawlereit?
A legegyszerűbb módszer a robots.txt fájl használata. Ebben külön szabályokat hozhatsz létre a GPTBot, az OAI-SearchBot vagy más OpenAI crawlerek számára. Így pontosan meghatározhatod, hogy mely robotok férhetnek hozzá a weboldaladhoz.
Honnan tudhatom, hogy járt-e nálam az OpenAI crawler?
A legmegbízhatóbb módszer a szervernaplók (server logok) elemzése. Ezekben látható a robot User-Agent neve, a látogatás időpontja, a lekért URL és a válaszkód. A GPTBot, az OAI-SearchBot vagy a ChatGPT-User könnyen azonosítható a naplófájlokban.
Befolyásolja a Google helyezéseimet, ha letiltom a GPTBotot?
Nem. A GPTBot letiltása nincs közvetlen hatással a Google keresőben elért helyezésekre, mert a Googlebot és az OpenAI crawlerei egymástól függetlenül működnek. Ugyanakkor a tiltás hatással lehet arra, hogy a weboldalad hogyan jelenik meg egyes OpenAI szolgáltatásokban.
Az OpenAI crawler ugyanúgy működik, mint a Googlebot?
Nem teljesen. Bár mindkettő feltérképezi a weboldalakat és elemzi azok tartalmát, eltérő célokat szolgálnak. A Googlebot a Google keresőindexét építi, míg az OpenAI crawlerei különböző AI-szolgáltatásokat támogatnak, például a ChatGPT Search működését vagy a felhasználók által kért weboldalak feldolgozását.
Milyen adatokat vizsgál egy OpenAI crawler?
Az OpenAI crawlerei többek között elemzik a szöveges tartalmat, a címsorokat, a belső és külső linkeket, a strukturált adatokat, a metaadatokat, a képek ALT szövegeit, valamint a weboldal technikai felépítését. Emellett igyekeznek felismerni az entitásokat és a témák közötti kapcsolatokat is.
Fontosak a strukturált adatok az OpenAI számára?
Igen. Bár az OpenAI nem részletezi pontosan, hogy milyen mértékben használja fel a Schema.org jelöléseket, a strukturált adatok egyértelműbbé teszik a weboldal tartalmát a crawlerek számára. Ez segíthet a szerzők, szervezetek, szolgáltatások és cikkek pontosabb értelmezésében.
Hogyan növelhetem az esélyét annak, hogy az AI rendszerek megértsék a weboldalamat?
Érdemes részletes és jól strukturált tartalmakat készíteni, logikus H1–H3 címsorokat használni, belső linkekkel összekapcsolni a kapcsolódó cikkeket, strukturált adatokat alkalmazni, valamint rendszeresen frissíteni a tartalmakat. Az AI rendszerek számára különösen fontos a topical authority, a hitelesség és a jól felépített tudásbázis.
Elég csak a robots.txt fájlra figyelni?
Nem. A robots.txt csupán azt szabályozza, hogy mely crawlerek férhetnek hozzá a weboldaladhoz. Ahhoz, hogy az AI rendszerek valóban értékes forrásként tekintsenek rád, szükség van magas minőségű tartalomra, technikailag megfelelő weboldalra, strukturált adatokra, belső linkelésre és folyamatos tartalomfrissítésre.
Mi a legfontosabb tanács az OpenAI crawlerekkel kapcsolatban?
Ne a crawlerek kijátszására törekedj, hanem arra, hogy olyan weboldalt építs, amely valódi értéket nyújt a látogatóknak. A részletes, hiteles, jól strukturált és rendszeresen frissített tartalom nemcsak a Google, hanem az OpenAI és más AI-alapú keresőrendszerek számára is hosszú távon értékesebb lesz.
Miért érdemes befektetni egy jó SEO szakértőbe?
A SEO ma már jóval többről szól, mint néhány kulcsszó optimalizálásáról. Az AI Overviews, a GEO (Generative Engine Optimization), a szemantikus SEO, az entitásalapú keresés és a topical authority korában azok a weboldalak kerülnek előnybe, amelyek valódi szakértői tudásközpontként jelennek meg a Google és az AI-alapú keresők számára.
Egy profi SEO szakértő nemcsak a jobb helyezések elérésében segít, hanem olyan hosszú távú stratégiát épít, amely növeli a weboldalad láthatóságát, erősíti a márkádat, és releváns érdeklődőket hoz az oldaladra. A megfelelően felépített SEO nem egyszeri költség, hanem olyan befektetés, amely hónapokon és éveken keresztül képes folyamatos forgalmat és új ügyfeleket generálni.
A keresési környezet folyamatosan változik. A Google algoritmusai, az AI-alapú találatok és a felhasználói szokások is egyre gyorsabban alakulnak. Egy tapasztalt SEO szakember segít alkalmazkodni ezekhez a változásokhoz, kiépíteni a szükséges topical authorityt, valamint olyan tartalomstratégiát kialakítani, amely nemcsak ma, hanem a jövő keresőiben is versenyképes marad. Egy rosszul kivitelezett SEO munka viszont könnyen idő-, pénz- és forgalomveszteséget okozhat, ezért különösen fontos, hogy a weboldalad optimalizálását valódi szakértőre bízd.

Miért érdemes választani a HonlapSEO-t?
Több éve foglalkozom keresőoptimalizálással, és munkám során nemcsak a hagyományos SEO-ra, hanem a modern keresési trendekre, az AI-alapú keresésekre és a GEO (Generative Engine Optimization) stratégiákra is kiemelt figyelmet fordítok. Segítek abban, hogy weboldalad ne csupán jobb helyezéseket érjen el a Google találati listáján, hanem az AI-alapú rendszerek, például a ChatGPT, a Google AI Overviews vagy a Perplexity számára is hiteles és könnyen feldolgozható forrássá váljon.
Szolgáltatásaim közé tartozik a SEO audit, a technikai optimalizálás, a kulcsszókutatás, a SEO szövegírás, a topical authority építés, a tartalomstratégia kialakítása, valamint a belső linkrendszer és a szemantikus SEO fejlesztése. Minden projekt során hosszú távú gondolkodásra törekszem, hiszen a cél nem csupán a rövid távú helyezésjavulás, hanem egy stabil, folyamatosan növekvő organikus jelenlét kialakítása. Ehhez a havidíjas SEO-t ajánlom.
Ha szeretnéd, hogy weboldalad valódi szakértői státuszt építsen ki a saját piacán, növelje a látogatottságát és felkészüljön az AI-alapú keresések jövőjére, szívesen segítek a megfelelő SEO és GEO stratégia kialakításában.
Keresőoptimalizáláshoz profi Seo szakembert keresel? Azonnal használható, gyors megoldások a Google irányelvei alapján. Megjelennél a a Google AI Overviews találataiban?
 Elérhetőségeim:
Elérhetőségeim:
Burai Barbi SEO szakember, SEO szakértő,
AI-GEO mentor
Telefon: +36-30-242-9494
E-mail: info(kukac)honlapseo.hu
Web: HonlapSEO SEO alapok
Eredményes keresőoptimalizáláshoz profi SEO szakembert keresel?
Vedd fel Velem a kapcsolatot az alábbi űrlap kitöltésével:


Google AI Overviews optimalizálás, Topical authority építés, GEO és AI keresőkre optimalizálás.
- OpenAI crawler útmutató - 2026-07-03
- Google AI crawler útmutató - 2026-07-02
- Topical authority építés esettanulmány – Hőszivattyús honlap - 2026-07-01